
HappyHorse 1.0: Key Facts
- What it does: Generates cinematic AI video from text or image, with audio and visuals created together in a single pass
- Why it stands out: Hit the highest Elo score ever recorded on Artificial Analysis, reaching 1,413 in image-to-video. No model has scored this high on the platform
- How to try it now: Public API opens April 30, 2026. Until then, the only verified access is through Artificial Analysis Video Arena
What Is HappyHorse 1.0? The Alibaba ATH Model That Hit #1 Before Anyone Knew Who Built It
Happy Horseの強みはマルチショットにあり。
— 田中義弘 | taziku CEO / AI × Creative (@taziku_co) April 9, 2026
複数の動画生成AIを試した結果、
HappyHorse-1.0は単発の見栄えだけでなく、
マルチショット生成のつながり方で何度も印象に残った。
まだ詳細発表前ではありますが非常に期待が持てるモデル。
via:@gmi_cloudpic.twitter.com/QJpkNZOWrl
HappyHorse 1.0 just became the highest-rated AI video model on Artificial Analysis Video Arena, and most people still have no idea what it is.
I was following the AI video space when it appeared. One day it was not there. The next, it was sitting at #1 with no company name, no press release, and no explanation. I went looking for answers.
The community spent three days guessing. Tencent, DeepSeek, startups. Everyone had a theory. Then on April 10, Alibaba’s ATH unit confirmed it through its official X account: HappyHorse 1.0 was built by Zhang Di’s team, the same people who built Kling at Kuaishou.
That last part is what made me pay attention. Kling did not come from nowhere either. Zhang Di has done this before.
In this guide, I cover what HappyHorse 1.0 is, how it compares with Seedance 2.0 and Kling 3.0, which fake sites to avoid, and how to test it right now for free.
HappyHorse 1.0 Leaderboard Results: Why It Ranks Above Seedance 2.0 Right Now
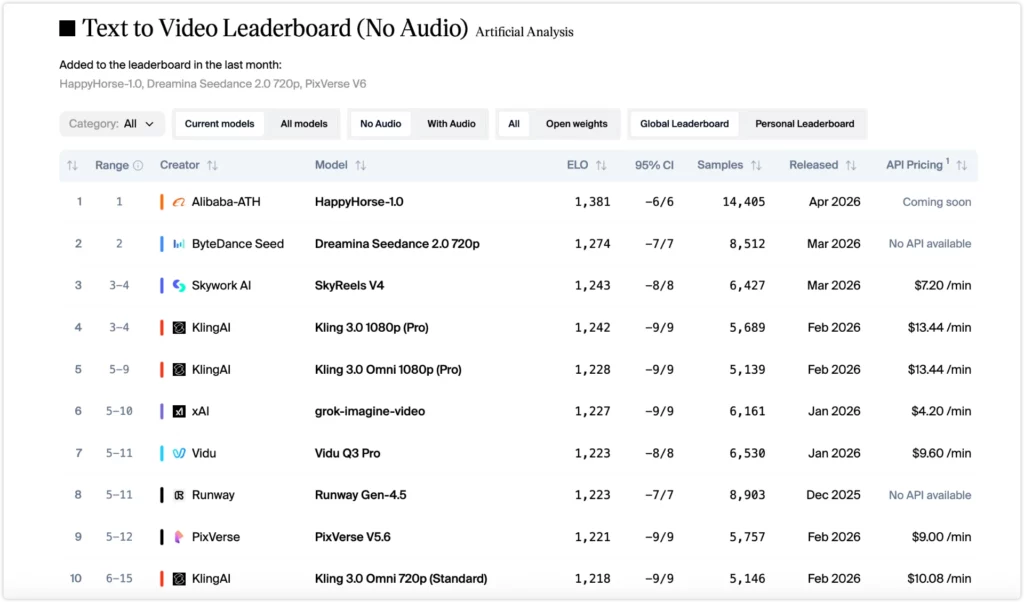
Artificial Analysis Video Arena ranks models through blind preference voting. Real users pick the better video without knowing which model made it. The scores reflect user preference, not independent lab results.
The no-audio gap is significant. A 110-point lead means roughly 6 in 10 users picked HappyHorse in a blind test. The I2V score of 1,413 is the highest the platform has ever recorded.
The with-audio category is a different story. Twelve points is too close to call. If audio sync drives your workflow, treat these two models as equal for now.
HappyHorse 1.0 vs. Top AI Video Models: Full Comparison
Here is how the current top models stack up. If you want to know which one fits your use case, the Best For row at the bottom is the fastest answer.
Seedance2.0を超えたと話題の『HappyHorse-1.0』
— GENEL | AIを用いた動画制作 (@genel_ai) April 8, 2026
結論としては、個人的にはまだSeedance 2.0のほうが品質高いかな?と思いました。
Seedance2.0のほうが動作が自然で、人物の見せ方もよく、全体の破綻も少ないように感じます。… pic.twitter.com/kDll6GQSS6
| Model | Best For | Strength | Weakness |
| HappyHorse 1.0 | Physics realism | Motion + audio sync | Faces weaker |
| Seedance 2.0 | Talking characters | Facial expression | Motion less natural |
| Kling 3.0 | 4K output | Resolution | Slower iteration |
| SkyReels V4 | Budget speed | Fast generation | Lower visual quality |
| PixVerse V6 | Quick clips | Ease of use | Less detailed output |
Want the full picture? Here is how all five models compare across nine dimensions.
| Dimension | HappyHorse 1.0 ⭐⭐⭐⭐⭐ | Seedance 2.0 ⭐⭐⭐⭐ | Kling 3.0 Pro ⭐⭐⭐⭐ | SkyReels V4 ⭐⭐⭐ | PixVerse V6 ⭐⭐⭐ |
| T2V Visual Quality | ✅ #1 (Elo 1,384) | ✅ #2 (Elo 1,274) | ✅ #4 (Elo 1,240) | ✅ #3 (Elo 1,243) | ⚠️ #5 (Elo 1,229) |
| I2V Visual Quality | ✅ #1 (Elo 1,413) | ✅ #2 (Elo 1,357) | ⚠️ #5 (Elo 1,298) | ❌ N/A | ✅ #4 (Elo 1,308) |
| Physics & Motion | ✅ Best in class | ✅ Strong | ✅ Strong | ⚠️ Good | ⚠️ Good |
| Character Animation | ⚠️ Good | ✅ Best in class | ✅ Best in class | ⚠️ Good | ⚠️ Good |
| Native Audio Sync | ✅ Joint generation | ✅ Strong | ⚠️ Limited | ⚠️ Basic | ⚠️ Limited |
| Max Resolution | ✅ 1080p | ⚠️ 720p | ✅ 1080p / 4K | ✅ 1080p | ✅ 1080p |
| Generation Speed | ✅ ~38s (reported) | ⚠️ Queue often | ✅ Fast | ✅ Fast | ✅ Fast |
| Public API | ⚠️ April 30 | ✅ Live | ✅ Live | ✅ Live | ✅ Live |
| Best For | Cinematic · Product | Characters · Audio | 4K · Multi-char | Budget · Speed | Quick clips |
What this means in plain terms:
Physics and motion: pick HappyHorse. Water, breaking glass, falling objects — these behave like real physics in available demos. The “AI jelly effect” that makes video look synthetic is noticeably less of a problem here than with most other models.
Human characters and faces: pick Seedance 2.0 or Kling 3.0. Both have much deeper investment in facial expression and character animation. If your content focuses on people talking, reacting, or moving naturally, HappyHorse is not the strongest choice right now.
Audio sync: too close to call. Twelve Elo points is not a real gap. Both models are competitive here. HappyHorse uses a newer joint-generation approach; Seedance 2.0 has more battle-tested audio output. Try both before committing.
4K output: only Kling 3.0 delivers it natively. If your delivery format requires 4K, Kling 3.0 is currently the only top-tier option that outputs it without upscaling.
HappyHorse 1.0 Key Features: What Public Reports Say About Native Audio, Lip-Sync, and Speed
A new video model dropped at #1 on the leaderboard 👀
— Justine Moore (@venturetwins) April 7, 2026
It's called HappyHorse-1.0, and it's currently leading in both text-to-video and image-to-video.
From my testing, it's particularly good at multi-shot videos and following detailed directions 👇 pic.twitter.com/byeCw90IEr
Most AI video models are built in two stages. Video is generated first, then audio is added separately and synced in post. HappyHorse 1.0 takes a different approach.
Public reports and available demos describe a single-stream Transformer architecture with 15 billion parameters that processes video and audio together in one pass. The practical result, based on demos available so far, is that ambient sound behaves like part of the scene rather than a layer added on top. A ball hitting a floor, water pouring, glass breaking, the audio starts and stops with the action because both were generated together.
Three capabilities come up consistently in reporting:
Native audio-video sync.
Sound is generated alongside the image, not after it. Early demos suggest environmental audio matches on-screen physics in a way that feels noticeably different from models that add audio as a separate step.
Multilingual lip-sync.
Public reports describe support for 7 languages including Mandarin, Cantonese, English, Japanese, Korean, German, and French. Pre-release testing indicates the approach adjusts facial muscle movement based on phoneme patterns for each language, rather than a simple overlay.
Generation speed.
Public reports describe generating a 5-second 1080p clip in roughly 38 seconds on a single H100 GPU, using what is described as an 8-step distilled inference process. These figures come from pre-release testing and should be treated as approximate until the public API launches and independent benchmarks are available.
HappyHorse 1.0 Fake Sites Warning: What Alibaba Group Actually Confirmed
Within 48 hours of HappyHorse hitting #1, dozens of fake sites appeared. Some looked convincing. Several GitHub repos appeared claiming to host model weights. Alibaba Group’s official posts confirmed the model is still in internal beta, with no public download available and no official consumer site yet.
Here is what is verified as of April 13, 2026:
| Source | Status |
| Alibaba ATH official Weibo | ✅ Confirmed |
| Artificial Analysis Video Arena | ✅ Real access, model randomly assigned |
| PhotoGrid integration | ✅ Live and direct |
| GitHub model weights | ❌ Not released — “coming soon” only |
| Any site charging monthly fees for HappyHorse access | ❌ Almost certainly fake |
| Any site offering weight downloads right now | ❌ Not from Alibaba |
The practical rule: if a site is asking you to pay a subscription or download files to access HappyHorse 1.0, leave. An overwhelming majority of those sites are repackaging older open-source models under the HappyHorse name. The official API does not open until April 30. Nothing before that is from Alibaba.
How to Try HappyHorse 1.0 Right Now: Video Arena and PhotoGrid
There are two legitimate ways to access HappyHorse output today.
Option 1: Artificial Analysis Video Arena
Go to artificialanalysis.ai/video/arena. Enter a text prompt or upload an image. The system assigns models randomly, so you will not always get HappyHorse. When you do, the output quality tends to be noticeably different from most other results. This is free but unpredictable.
Option 2: PhotoGrid
PhotoGrid has integrated HappyHorse 1.0 directly into its AI video tools. You get HappyHorse every time, not a lottery. Two modes are available right now:
- Text to Video: Write a prompt and generate a HappyHorse-powered clip. Try it here
- Image to Video: Upload any photo and bring it to life with HappyHorse motion. Try it here
This is the fastest path to HappyHorse output before the public API opens on April 30.
HappyHorse 1.0 Prompts: 6 Copy-Paste Examples with Key Trigger Words
🔥Happy Horse 1.0今天登顶,具体表现如何?能不能打败Seedance2.0,大家自己看样片判断一下。 pic.twitter.com/Xqt0n18GD2
— 肖师傅 (@xiaojietongxue) April 8, 2026
These prompts are based on community testing across Reddit, X, and Video Arena. Each one includes a trigger phrase that HappyHorse responds to particularly well. The model is sensitive to specific language around audio and physics in a way most other models are not.
For audio-video sync (trigger: “high-fidelity ambient sound”):
“Cinematic close-up of a glass shattering on a stone floor, high-fidelity ambient sound of breaking, slow motion, natural lighting.”
For lip-sync content (trigger: “synchronized phonetic lip movement”):
“Portrait of a woman speaking directly to camera, synchronized phonetic lip movement, hyper-realistic skin texture, soft studio lighting.”
For physics realism (trigger: “dynamic particle interaction”):
“A golden retriever running through deep snow, dynamic snow particle interaction, 4K, cinematic tracking shot.”
For multi-angle consistency:
“A person walking along a beach at golden hour, camera tracking from behind, cut to front-facing close-up, same lighting throughout.”
For product showcase:
“A skincare bottle rotating slowly on a white surface, soft natural light from the left, camera pulls back to reveal full label, high-fidelity ambient sound of quiet room.”
For image-to-video (trigger: “natural motion, stable background”):
“Keep the same face. Add natural head movement and a slight smile. Natural motion, stable background.”
One pattern that shows up consistently: HappyHorse responds better to prompts that describe the sound environment alongside the visual. Adding phrases like “high-fidelity ambient sound” or specifying what audio should be present tends to produce more coherent output than treating audio as an afterthought.
HappyHorse 1.0 FAQs
Is HappyHorse 1.0 officially released?
No. As of April 13, 2026, it is in internal beta. The public API is expected to open around April 30, 2026.
Is HappyHorse 1.0 open source?
This is unclear. Early reports described it as open weights, but no model files have been officially released. Alibaba’s current positioning is API-first. Any repo claiming to have weights right now is not from Alibaba.
What does #1 on Video Arena actually mean?
It means HappyHorse won the most head-to-head blind preference votes among real users comparing it to other models. It reflects user preference on visual quality, not an automated benchmark. Some observers note that outputs can potentially be optimized for arena-style testing, so treat it as strong signal rather than definitive proof.
Who built HappyHorse 1.0?
Alibaba’s ATH Innovation unit, led by Zhang Di, former VP at Kuaishou and technical lead of Kling.
Where can I try it safely right now?
Artificial Analysis Video Arena (random assignment) or PhotoGrid, which has direct HappyHorse integration for both text-to-video and image-to-video.
Can I use HappyHorse outputs commercially?
Alibaba has not published commercial terms yet. Wait for the official API launch and usage terms before using outputs in paid client work or advertising.
HappyHorse 1.0 API Opens April 30: What It Means for Creators
PhotoGrid also gives you access to other top models including Kling, Veo, Sora, Hailuo, and PixVerse, all in one place. If you want to compare outputs across models without switching platforms, that is the most practical setup right now.
HappyHorse 1.0 is the highest-rated AI video model on Artificial Analysis right now. It generates video and audio together in a single pass, handles complex prompts well, and produces physics that most other models still struggle with.
The public API reportedly opens April 30, 2026. Until then, the fastest way to test it is on PhotoGrid, which has already integrated HappyHorse directly. No waitlist, no lottery.





